Beyond Dictation: How Semantic ASR is Making Voice Recognition Smarter
We've all been there. You're trying to use a voice-to-text feature, and it feels like you're talking to a very literal-minded alien. You say, "I need to buy milk, bread, and eggs." and it types out "I need to buy milk bread and eggs" - a grocery list that's suddenly a lot less useful. Or you're dictating an email, and you have to say "period" and "new paragraph" like you're a human punctuation mark. It's clunky, it's unnatural, and frankly, it's not much faster than typing.
For decades, this was the reality of voice recognition. It was a tool for simple dictation, a technology that could hear our words but couldn't understand our meaning. But in recent years, a quiet revolution has been taking place, a shift from mere transcription to genuine understanding. The driving force behind this transformation is a powerful technology called Semantic Automatic Speech Recognition (Semantic ASR) and Conversational AI.
Semantic ASR is the secret sauce that's making modern voice recognition systems not just faster, but smarter. It's the difference between a tool that simply converts sound into text and an intelligent assistant that understands context, corrects grammar on the fly, and even formats your writing for you.
In this article, we'll take a deep dive into the world of semantic ASR. We'll explore what it is, how it's transforming voice recognition, and what this means for both the developers building the future of AI and the productivity enthusiasts looking for new ways to work smarter, not harder.
Traditional Voice Recognition
Before we can fully appreciate the leap forward that semantic ASR represents, we need to understand where we've come from. The history of voice recognition is a fascinating journey, one that starts with humble beginnings and a whole lot of patience.
The Early Days
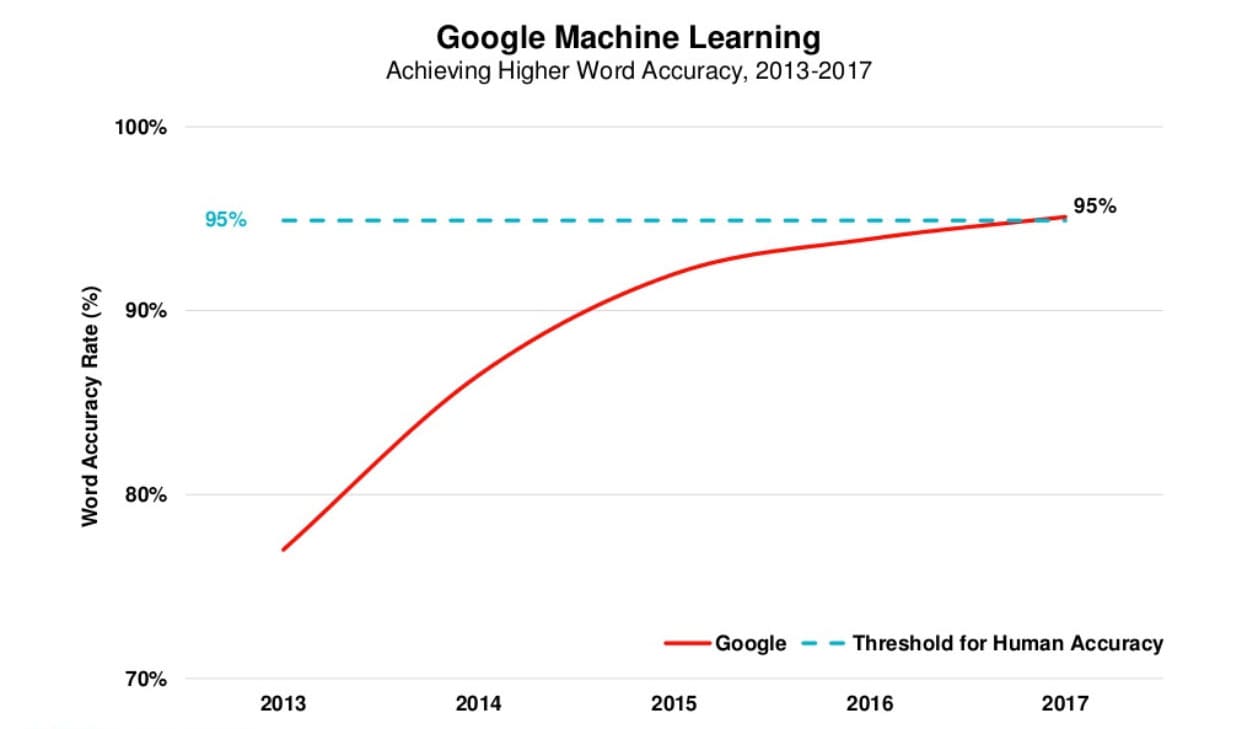
The dream of talking to computers is almost as old as computers themselves. In the 1950s, Bell Laboratories developed a system called "Audrey" that could recognize a single voice speaking digits aloud [1]. A decade later, IBM introduced "Shoebox," which could understand a whopping 16 words in English [1]. These early systems were groundbreaking for their time, but they were a far cry from the seamless voice assistants we have today. They were limited, they were expensive, and they were a long way from being practical for everyday use.
The Rise of Dictation Software
The 1990s saw the arrival of the personal computer, and with it, a new wave of voice recognition software. The most iconic of these was Dragon NaturallySpeaking. For the first time, voice recognition was accessible to the general public, and it found a niche with professionals who needed to dictate long documents, such as doctors and lawyers. Dragon was a game-changer, but it still had its limitations.
The Limitations of Traditional Systems

Traditional dictation software, for all its innovation, was fundamentally a sound-to-word converter. It was a tool of transcription, not of understanding. This led to a number of frustrations for users:
- Lack of Context Awareness: These systems had no real understanding of the content they were transcribing. They couldn't tell the difference between “I'm going to the store” and “I'm going to the store, period.” This meant that users had to explicitly state all punctuation and formatting commands.
- The Need for Explicit Commands: The interaction model was rigid and unnatural. Users had to learn a whole new vocabulary of commands to get the software to do what they wanted. It was a far cry from a natural conversation.
- The "Robotic" Experience: The combination of a lack of context awareness and the need for explicit commands created a user experience that felt robotic and clunky. It was a tool you had to adapt to, rather than a tool that adapted to you.
- Accuracy Issues: While accuracy improved over time, traditional systems still struggled with accents, background noise, and specialized terminology. This meant that users often had to spend a significant amount of time editing the transcribed text.
In short, traditional voice recognition was a powerful tool, but it was a tool that required a lot of work to use effectively. It was a far cry from the seamless, intuitive voice assistants we have today. And the key difference between then and now can be summed up in two words: semantic ASR.
What is Semantic ASR?
So, what exactly is this magical thing called semantic ASR? At its core, semantic ASR is a branch of artificial intelligence that focuses on understanding the meaning of language. It's about going beyond the literal words on a page and grasping the underlying intent, context, and relationships within the text. Think of it like this: a traditional voice recognition system is like someone who can hear the words you're saying but doesn't understand the language. A semantic ASR system, on the other hand, is like a fluent speaker who not only hears the words but also understands the meaning behind them.
Core Concepts of Semantic Analysis
To understand how semantic ASR works, we need to look at some of the core concepts of semantic analysis, the building blocks of understanding:
- Lexical Semantics: This is the most basic level of semantic analysis. It's about understanding the meaning of individual words, the kind of definition you'd find in a dictionary.
- Compositional Semantics: This is where things get more interesting. Compositional semantics is about understanding how words combine to create meaning in a sentence. For example, the sentences “The dog chased the cat” and “The cat chased the dog” use the same words, but they have completely different meanings. Compositional semantics is what allows an AI to understand this difference.
- Word Sense Disambiguation: Many words have multiple meanings. The classic example is the word “bark.” It can mean the sound a dog makes, or it can mean the outer layer of a tree. Word sense disambiguation is the process of using context to determine the correct meaning of a word. A semantic ASR system can look at the other words in a sentence to figure out which meaning of “bark” is the right one.
- Relationship Extraction: This is about identifying the entities in a text (people, places, organizations, etc.) and understanding the relationships between them. For example, in the sentence “Apple was founded by Steve Jobs and Steve Wozniak,” a semantic ASR system can identify Apple, Steve Jobs, and Steve Wozniak as entities and understand that the relationship between them is that of a company and its founders.
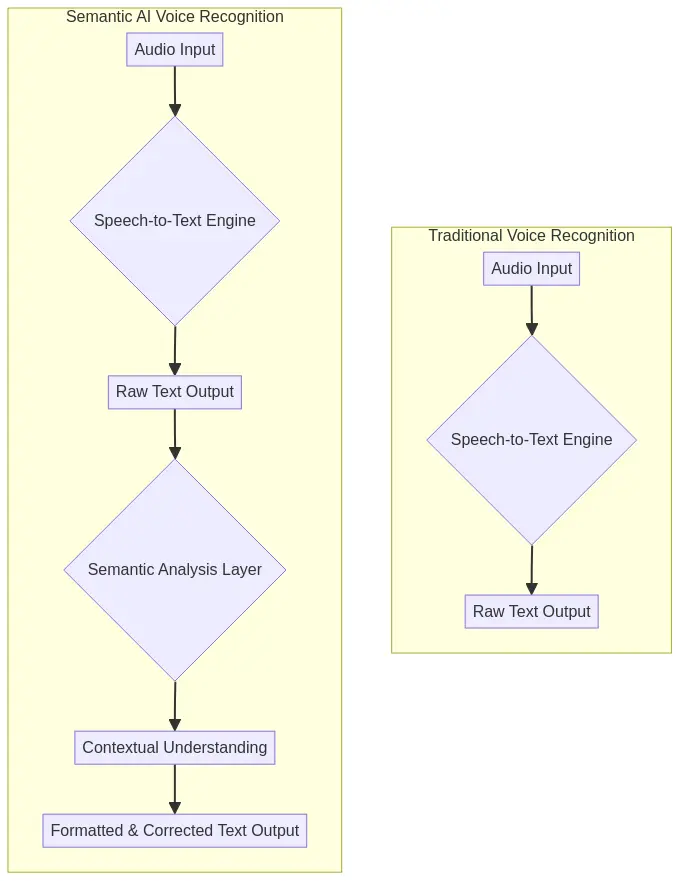
By combining these different levels of analysis, semantic ASR can build a rich, nuanced understanding of language. It's a far cry from the simple word-for-word transcription of traditional voice recognition systems. And it's this deep understanding of language that is revolutionizing the way we interact with our devices.
How Semantic ASR is Improving Voice Recognition

Now that we have a better understanding of what semantic ASR is, let's look at how it's being used to create a new generation of intelligent voice recognition systems. The magic of semantic ASR lies in its ability to go beyond simple transcription and provide a whole range of features that make voice recognition more natural, more intuitive, and more powerful.
Context Awareness in Action
One of the biggest breakthroughs of semantic ASR is context awareness. A semantic ASR system can understand the context of what you're saying, and it can use that understanding to provide a more intelligent and helpful response. For example, if you're dictating an email and you say “send it to John,” a semantic ASR system can look at your contacts, find the John you email most often, and automatically add his email address to the “To” field. It's a small thing, but it's a perfect example of how context awareness can make voice recognition feel more like a conversation with a helpful assistant.
Automatic Text Formatting
Another area where semantic ASR is making a big impact is in automatic text formatting. Traditional voice recognition systems require you to explicitly state all punctuation and formatting commands. With a semantic ASR system, you can just speak naturally, and the system will automatically add the correct punctuation, capitalization, and paragraph breaks. It can even format your text for specific applications, like adding bullet points to a list or formatting code in a code editor.
Intelligent Grammar Correction
We all make mistakes when we're speaking. We use filler words like “um” and “ah,” we start sentences and then change our minds, and we sometimes make grammatical errors. A semantic ASR system can understand these imperfections in our speech and automatically correct them. It can remove filler words, fix grammatical errors, and even rephrase sentences to make them more clear and concise. It's like having a built-in proofreader that cleans up your writing as you speak.
Advanced Capabilities
Beyond these core features, semantic ASR is also enabling a whole range of advanced capabilities that are transforming voice recognition from a simple dictation tool into a powerful productivity platform. These include:
- Speaker Diarization: The ability to distinguish between different speakers in a conversation. This is incredibly useful for transcribing meetings and interviews.
- Summarization and Key Takeaway Extraction: A semantic ASR system can analyze a long dictation and automatically pull out the most important points. This can be a huge time-saver for anyone who needs to quickly get up to speed on a long conversation or meeting.
These are just a few examples of how semantic ASR is revolutionizing voice recognition. By going beyond simple transcription and providing a deep understanding of language, semantic ASR is creating a new generation of voice recognition systems that are more natural, more intuitive, and more powerful than ever before.
A Deep Dive into WhisperBro
To see the power of semantic ASR in action, let's review WhisperBro. WhisperBro is a next-generation voice-to-text tool that is built from the ground up with semantic ASR at its core. It's a good example of semantic ASR creating a voice recognition experience that is truly smart.
Context-Aware Formatting
One of the standout features of WhisperBro is its context-aware formatting. WhisperBro can understand the context of where you're using it, and it can automatically format your text accordingly. For example, if you're writing an email, WhisperBro will automatically add a salutation and a closing. If you're writing a list, it will automatically add bullet points. And if you're writing code, it will automatically format your code with the correct indentation and syntax highlighting. It's a small thing, but it's a perfect example of how semantic ASR can make voice recognition feel more like a conversation with a helpful assistant.
Smart Edits
Another area where WhisperBro shines is in its smart edits. WhisperBro can understand the imperfections in our speech and automatically correct them. It can remove filler words, fix grammatical errors, and even rephrase sentences to make them more clear and concise. It's like having a built-in proofreader that cleans up your writing as you speak.
AI Commands
WhisperBro also includes a powerful feature called AI Commands. With AI Commands, you can use natural language to edit and format your text. For example, you can say “bold the last sentence,” “make that a bulleted list,” or “translate that to Spanish.” It's a much more natural and intuitive way to interact with your text than using a traditional menu-based interface.
WhisperBro is a powerful tool that showcases the potential of semantic ASR to transform voice recognition. By going beyond simple transcription and providing a deep understanding of language, WhisperBro is creating a voice recognition experience that is more natural, more intuitive, and more powerful than ever before.
The Modern Voice Recognition Landscape
WhisperBro is a powerful tool, but it's not the only game in town. The modern voice recognition landscape is a vibrant and competitive space, with a number of different tools vying for the top spot. To help you navigate this landscape, we've put together a friendly neighborhood showdown of some of the most popular voice recognition tools on the market today.
| Feature | WhisperBro | Microsoft Word Dictate | Otter.ai | Dragon Professional Anywhere |
|---|---|---|---|---|
| Best For | All-purpose, high-quality text generation | General users, free and easy access | Meeting transcription and collaboration | Professionals with specific industry needs |
| Semantic ASR | Deep semantic understanding | Basic semantic features | Advanced speaker diarization | Industry-specific vocabularies |
| Context-Aware Formatting | Yes | No | No | Limited |
| Smart Edits | Yes | No | No | No |
| AI Commands | Yes | No | No | Yes |
| Pricing | Freemium | Free with Microsoft 365 | Freemium | Subscription-based |
Microsoft Word Dictate
Microsoft Word Dictate is the elephant in the room. It's free, it's built into the most popular word processor on the planet, and it's surprisingly accurate. For most people, it's the first and only voice recognition tool they'll ever need. However, it's also a fairly basic tool. It lacks the advanced semantic features of a tool like WhisperBro, and it's not as well-suited for specialized tasks like meeting transcription or coding.
Otter.ai
Otter.ai is a specialist. It's designed from the ground up for meeting transcription, and it's very, very good at it. It can distinguish between different speakers, it can generate a summary of the key takeaways from a meeting, and it can even integrate with your calendar to automatically record and transcribe your meetings. However, it's not as well-suited for general-purpose dictation as a tool like WhisperBro.
Dragon Professional Anywhere
Dragon Professional Anywhere is the old guard. It's been around for decades, and it's still the go-to choice for many professionals, particularly in the legal and medical fields. Its biggest strength is its deep, industry-specific vocabularies. It can understand the complex terminology of these fields with a high degree of accuracy. However, it's also the most expensive tool on this list, and it has a steeper learning curve than the other tools.
Where WhisperBro Fits In
So, where does WhisperBro fit into this competitive landscape? WhisperBro is the all-rounder. It's a powerful tool that can handle a wide range of tasks, from general-purpose dictation to meeting transcription to coding. Its deep semantic understanding allows it to generate high-quality text in a variety of different contexts. And its intuitive interface and powerful AI Commands make it a joy to use.
What's Next for Voice Recognition?
The world of voice recognition is moving at a breakneck pace. The advancements of the last few years have been nothing short of astounding, and the future promises to be even more exciting. So, what's next for voice recognition? Here are a few of the trends that we're most excited about:
Ambient AI
Ambient AI is the idea of voice assistants that are always on, always listening, and always ready to help. They're seamlessly integrated into our environment, and they can anticipate our needs before we even have to ask. Imagine a world where your voice assistant can automatically order you a pizza when it hears you say you're hungry, or where it can automatically book you a flight when it hears you say you need to go to a conference. It's a world that's not as far off as you might think.
Emotional Tone Recognition
Another exciting area of research is emotional tone recognition. This is the ability of an AI to understand not just what we're saying, but also how we're feeling. It can analyze the tone, pitch, and cadence of our voice to determine whether we're happy, sad, angry, or surprised. This could have a huge impact on a wide range of applications, from customer service to mental health.
Deeper Workflow Integration
Finally, we're going to see a deeper integration of voice recognition into our workflows. Voice is a natural and intuitive way to interact with our devices, and we're going to see it become a primary input method for a wide range of software and devices. Imagine a world where you can use your voice to control your entire computer, from opening and closing applications to editing documents and sending emails. It's a world that's not just possible, but probable.
Conclusion
The journey of voice recognition has been a long and fascinating one. From the early days of simple dictation to the modern era of semantic ASR, we've seen a technology that has gone from a clunky and frustrating tool to a powerful and intuitive assistant. The key to this transformation has been semantic ASR, a technology that has allowed us to go beyond simple transcription and create voice recognition systems that can truly understand our meaning.
WhisperBro is a perfect example of the power of semantic ASR in action. It's a tool that is as powerful as it is versatile, and it's a great choice for anyone who wants to take their voice recognition to the next level. But WhisperBro is just the beginning. The future of voice recognition is bright, and we can't wait to see what's next.
If you're ready to experience the future of voice recognition for yourself, we encourage you to give WhisperBro a try.