What is Automatic Speech Recognition (ASR)? A Deep Dive
Ever found yourself talking to your phone, asking for directions, or dictating a text message? Or maybe you've seen live captions pop up during a video call and wondered how they appear so quickly. Behind these seemingly magical experiences is a technology that has been decades in the making: Automatic Speech Recognition, or ASR. It's the engine that turns the spoken words into written text.
This isn't just about simple dictation anymore. We're entering an era where ASR is becoming more intelligent, more context-aware, and more deeply integrated into our lives than ever before. For AI and machine learning developers, this opens up a universe of possibilities for creating smarter applications. For anyone passionate about productivity, it offers new ways to save time and streamline workflows.
In this article, we will start with the basics, explaining what ASR is and how it works in simple terms. Then, we'll travel back in time to uncover ASR history, from a machine that could only recognize numbers to the sophisticated digital assistants we know today. Finally, we'll explore the new wave of ASR, powered by the new Transformer technology behind ChatGPT, and discover how it's making speech recognition more semantic, flexible, and powerful than we ever imagined.
So, grab your cup of coffee, and let's dive in. We will see that the future of how we interact with technology is not about typing, it's about talking.
What Exactly is ASR?
At its core, Automatic Speech Recognition is the technology that allows computers and devices to understand and convert human speech into text. It's often used interchangeably with the term Speech-to-Text (STT). Think of it as a universal translator, but instead of translating between two different languages, it translates between two different forms of communication: sound waves and digital text.
But before we go deeper, it's important to clear up a common point of confusion: the difference between speech recognition and voice recognition.
- Speech Recognition is about understanding what is being said. Its goal is to accurately transcribe the words spoken, regardless of who the speaker is.
- Voice Recognition (or speaker recognition) is about identifying who is speaking. Its goal is to verify a person's identity based on their unique vocal characteristics.
So, when you ask your smart speaker to play a song, it uses speech recognition to understand your command. When your banking app uses your voice to grant you access to your account, it's using voice recognition. For the rest of this article, our focus is squarely on the first—the incredible tech that understands the words you say.
How Does ASR Work?
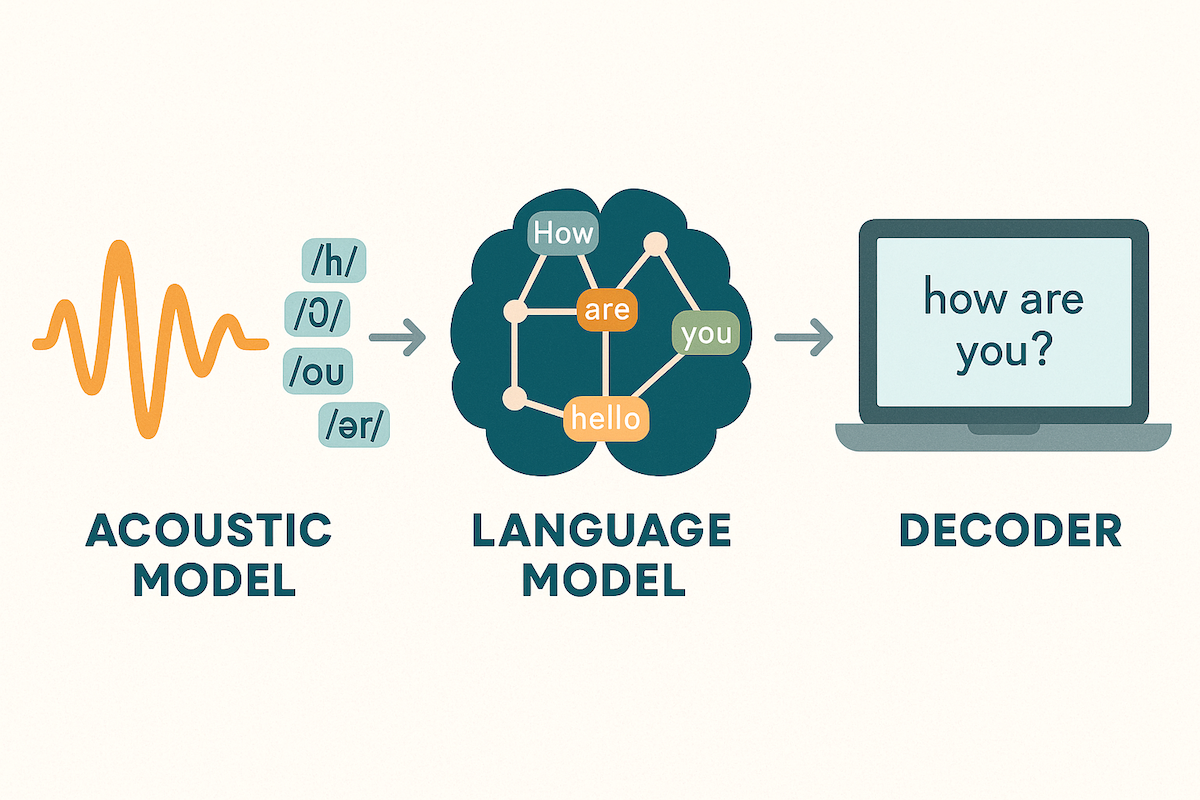
Imagine you're trying to decipher a friend's handwriting. First, you look at the individual letters (the acoustic features). Then, you consider how those letters form words (the vocabulary). Finally, you think about how those words fit together to make a coherent sentence (the grammar and context). ASR does something very similar, but with sound.
An ASR system is typically built from several key components:
-
The Acoustic Model: This is the system's "ear." It listens to the audio and breaks it down into tiny sound units called phonemes. For example, the word "cat" is made up of three phonemes: /k/, /æ/, and /t/. The acoustic model analyzes the audio waveform and predicts which phonemes are being spoken at any given moment.
-
The Language Model: This is the system's "brain." Once the acoustic model has a sequence of phonemes, the language model steps in to figure out the most likely sequence of words. It acts like a sophisticated spell-checker, using its knowledge of grammar, syntax, and common word combinations to turn a string of sounds into a readable sentence. For example, if it hears something that sounds like "ice cream" and "I scream," the language model knows that "I scream for ice cream" is a much more probable sentence.
-
The Decoding Process: This is where the magic happens. The decoder is an algorithm that combines the predictions from the acoustic model and the language model to produce the final text transcription. It searches through all the possible word combinations to find the one that best matches both the audio input and the rules of the language.
This traditional approach, often using statistical methods like Hidden Markov Models (HMMs), has been the backbone of ASR for many years. However, as we'll see, a new generation of models is changing the game entirely.
The 70-Year History of ASR
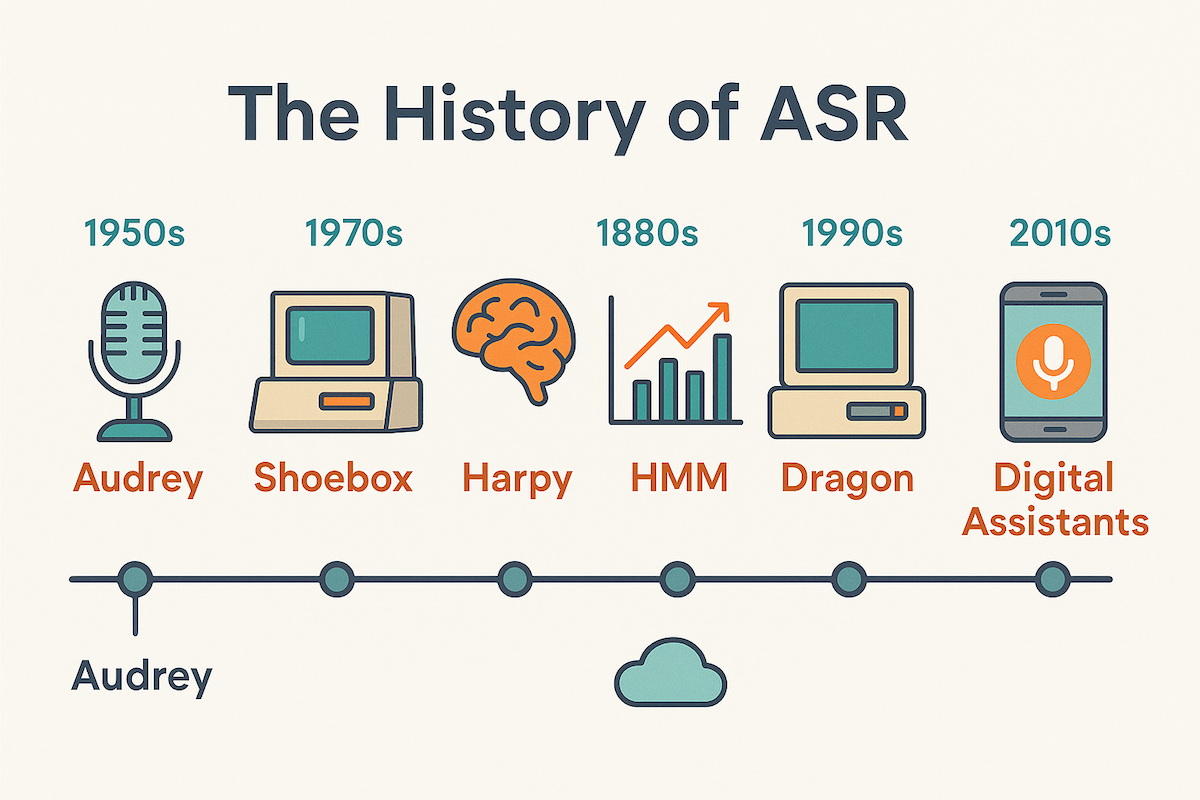
The path to modern ASR is a long and winding one, filled with brilliant minds and technological leaps. What started as a simple experiment in a lab has evolved into a technology that is reshaping our world. Let's take a walk through the key milestones.
| Decade | Key Milestone(s) | Significance |
|---|---|---|
| 1950s | Bell Labs' "Audrey" | The very first ASR system. It could recognize spoken digits (0-9) from a single voice with about 90% accuracy. A monumental first step. |
| 1960s | IBM's "Shoebox" | Building on Audrey, Shoebox could understand 16 English words and simple mathematical commands. |
| 1970s | Carnegie Mellon's "Harpy" | Funded by DARPA, Harpy could understand over 1,000 words—the vocabulary of a three-year-old. It introduced new methods for handling sentence structure. |
| 1980s | The Hidden Markov Model (HMM) | This statistical model revolutionized ASR. Instead of matching rigid patterns, HMMs used probabilities to determine the most likely word sequence, making systems more flexible and accurate. |
| 1990s | The Rise of Consumer ASR | With the advent of more powerful PCs, the first consumer dictation software, Dragon Dictate, was released. For the first time, people could talk to their computers and see their words appear on screen. |
| 2000s | Google and Big Data | Google launched its Voice Search app. This was a game-changer because it leveraged the power of the cloud and massive datasets (billions of user search queries) to train its models, dramatically improving accuracy. |
| 2010s | The Age of Digital Assistants | Apple's Siri (2011), followed by Amazon's Alexa and Google Assistant, brought ASR into the mainstream. These assistants made voice interaction a daily habit for millions. |
From a machine that could barely count to ten, to a world where we can have conversations with our devices, the evolution of ASR has been nothing short of extraordinary. But the biggest leap was yet to come.
The Transformer Revolution: A New Wave of Intelligent ASR
For years, ASR systems got progressively better, but they still struggled with the nuances of human speech—accents, background noise, slang, and, most importantly, context. The traditional models, like HMMs, were good at predicting the next word in a sequence, but they didn't truly understand the meaning behind the words.
Then came the Transformer.
First introduced in a 2017 paper by Google researchers, the Transformer is a novel neural network architecture that has completely revolutionized the field of AI, particularly in Natural Language Processing (NLP). It's the technology that powers large language models like ChatGPT. And now, it's doing the same for ASR.
What Makes Transformers So Special?
To understand the impact of Transformers, let's use another analogy. Imagine you're reading a book. Older models, like Recurrent Neural Networks (RNNs), read the book one word at a time, from beginning to end. They have to remember all the previous words to understand the current one, which is like trying to remember the entire plot of a novel by the time you reach the last page. It's difficult, and they often forget important details from early on.
Transformers, on the other hand, can read the entire book at once. They use a mechanism called attention, which allows them to weigh the importance of all the words in the input simultaneously. They can see how the word "it" in a sentence refers back to "the dog" mentioned several paragraphs earlier. This ability to process the entire context at once gives them a much deeper and more nuanced understanding of language.
Whisper: ASR on a Whole New Level
A prime example of the Transformer's impact on ASR is OpenAI's Whisper. Released in 2022, Whisper represents a monumental leap forward. Here's why:
-
Massive and Diverse Training Data: Whisper was trained on an unprecedented 680,000 hours of audio data collected from the internet. This data is not only vast but also incredibly diverse, covering a wide range of languages, accents, topics, and acoustic conditions. This is a stark contrast to older systems that were trained on just a few hundred hours of clean, carefully curated audio.
-
End-to-End Architecture: The Whisper architecture is a simple end-to-end Transformer. It takes raw audio as input and directly outputs the transcribed text. This simplifies the complex, multi-stage pipeline of traditional ASR systems (acoustic model, language model, decoder) into a single, elegant model.
-
Robustness and Accuracy: Because of its training on messy, real-world data, Whisper is incredibly robust. It handles background noise, accents, and technical jargon with an accuracy that was previously unattainable. It approaches human-level performance across a wide variety of tasks.
The Rise of Semantic ASR
The introduction of Transformer-based models like Whisper is ushering in a new era of semantic ASR. This is where the technology moves beyond simple transcription to a deeper understanding of the speech itself. Because these models are trained on so much data, they learn not just the words, but the relationships between them—the semantics.
This means modern ASR systems can perform tasks that were once the exclusive domain of NLP models, such as:
- Punctuation and Capitalization: Automatically adding commas, periods, and capital letters to make the text readable.
- Speaker Diarization: Identifying who spoke and when, even in a conversation with multiple people.
- Sentiment Analysis: Determining the emotional tone of the speaker (positive, negative, neutral).
- Topic Detection and Summarization: Identifying the key topics in a long recording and even generating a concise summary.
A good example of this new generation of semantic ASR in action is WhisperBro, an AI-powered voice-to-text tool that goes far beyond simple transcription. Unlike traditional voice-to-text software that merely converts speech to text, WhisperBro leverages semantic AI to understand context, automatically correct grammar, add proper punctuation, and format text based on where you're using it. Whether you're composing an email, filling out a form, or writing code, the system adapts to provide perfectly formatted output. This represents the practical application of semantic ASR—technology that doesn't just hear what you say, but understands what you mean and how you want it presented.
For developers, this means you no longer need to stitch together separate ASR and NLP systems. You can get rich, structured data directly from the audio. For productivity enthusiasts, this means tools that can not only type what you say but also organize your thoughts, identify action items from a meeting, and even gauge customer sentiment from a sales call.
Key Technical Advances in Modern ASR
The shift from traditional statistical models to Transformer-based architectures has brought several key improvements:
| Traditional ASR (HMM-based) | Modern ASR (Transformer-based) |
|---|---|
| Sequential Processing: Processes audio one frame at a time | Parallel Processing: Processes entire audio sequence simultaneously |
| Limited Context: Struggles with long-range dependencies | Global Context: Understands relationships across entire input |
| Multi-Stage Pipeline: Separate acoustic, language, and decoding models | End-to-End: Single model handles entire transcription process |
| Clean Data Training: Requires carefully curated, noise-free audio | Robust Training: Learns from messy, real-world data |
| Word-Level Accuracy: Focuses on individual word recognition | Semantic Understanding: Grasps meaning and context |
Real-World Applications of ASR
The advances in ASR technology have opened up a world of practical applications that are transforming industries and improving lives. Here are some key areas where modern ASR is making a significant impact:
Healthcare and Medical Documentation
Medical professionals are using ASR to streamline documentation processes. Instead of spending hours typing patient notes, doctors can now dictate their observations and have them automatically transcribed and formatted. Advanced systems can even recognize medical terminology and suggest appropriate codes for billing purposes.
Accessibility and Inclusion
ASR technology is breaking down barriers for people with hearing impairments through real-time captioning services. It's also helping individuals with mobility limitations who may find typing difficult or impossible. Voice-controlled interfaces allow people to interact with technology in ways that were previously inaccessible.
Business and Productivity
From automated meeting transcriptions to voice-powered customer service systems, ASR is revolutionizing how businesses operate. Sales teams can focus on conversations rather than note-taking, knowing that AI will capture and analyze the key points. Customer service representatives can access real-time suggestions based on what customers are saying.
Content Creation and Media
Podcasters, journalists, and content creators are leveraging ASR to quickly transcribe interviews and generate searchable content. Video platforms use ASR to automatically generate captions, making content more accessible and improving search engine optimization.
Challenges and Future Directions
Despite the remarkable progress, ASR technology still faces several challenges that researchers and developers are actively working to address:
The Accuracy Challenge
While modern ASR systems approach human-level performance in ideal conditions, they still struggle with certain scenarios. Heavy accents, background noise, overlapping speakers, and domain-specific jargon can significantly impact accuracy. The goal of achieving 100% accuracy across all conditions remains elusive.
Privacy and Security Concerns
As ASR systems become more prevalent, concerns about data privacy and security have grown. Voice data is highly personal, and users are increasingly aware of how their speech is being processed, stored, and potentially shared. Companies are responding by developing on-device processing capabilities and implementing stronger privacy protections.
Bias and Fairness
ASR systems can exhibit bias based on the data they're trained on. If training data predominantly features certain accents, dialects, or demographics, the system may perform poorly for underrepresented groups. Ensuring fair and equitable performance across diverse populations is an ongoing challenge.
The Path Forward: Self-Supervised Learning
The future of ASR lies in self-supervised learning, a technique that allows models to learn from vast amounts of unlabeled audio data. Instead of requiring expensive human transcriptions, these systems can discover patterns and structures in speech automatically. This approach promises to make ASR more accurate, more accessible, and capable of handling a broader range of languages and dialects.
Companies like Meta have already demonstrated the potential of this approach with models like wav2vec 2.0, which learns speech representations from raw audio without requiring transcriptions. As these techniques mature, we can expect ASR systems to become even more powerful and widely available.
Conclusions
We've come a long way from Audrey, the digit-recognizing machine of the 1950s. Today, ASR is a powerful, accessible technology that is still evolving at a fast pace. The integration of Transformer architectures has not only improved accuracy but has fundamentally changed what's possible with speech recognition technology.
The shift from simple transcription to semantic understanding represents a paradigm change. We're moving toward a world where machines don't just hear our words—they understand our intent, context, and meaning. This opens up possibilities we're only beginning to explore: AI assistants that truly understand nuance, accessibility tools that adapt to individual needs, and productivity applications that can think alongside us.
While challenges remain—such as achieving perfect accuracy for every dialect, ensuring user privacy, and addressing bias—the trajectory is clear. The shift towards self-supervised learning, where models can learn from vast amounts of unlabeled audio data, promises even greater accuracy and accessibility in the years to come.
Automatic Speech Recognition is no longer a futuristic novelty; it's a fundamental part of the modern technological landscape. It's breaking down communication barriers, unlocking insights from spoken data, and changing the very nature of how we interact with the digital world. From healthcare documentation to real-time translation, from accessibility tools to creative applications, ASR is quietly revolutionizing how we work, communicate, and live.
The next time you talk to your device, dictate a message, or see captions appear on a video, take a moment to appreciate the incredible journey of innovation that made it possible. From Bell Labs' Audrey to OpenAI's Whisper, from statistical models to neural networks, from simple digit recognition to semantic understanding—we've witnessed seven decades of relentless progress.
Interested in semantic ASR? Check out WhisperBro, an AI-powered voice-to-text tool that leverages the latest in ASR technology to deliver context-aware, perfectly formatted transcriptions for any application.